exec_simple_query
简要介绍一下 PostgreSQL 的执行流程。首先,我们需要明确 PostgreSQL 是基于多进程开发的,每当一个连接请求过来,PostgreSQL 都将创建一个新的 postgres 进程用于处理用户请求,在用户将需要执行的 SQL 语句发送到后端之后,postgres 进程将从 exec_simple_query() 函数开始进行处理,其主要的流程如下:
- 调用 pg_parse_query() 函数进行词法、语法分析,即我们上面介绍的内容;
- 循环遍历解析树链表对每个语句进行处理,如果没有查询语句转步骤 7;
- 调用 pg_analyze_and_rewrite() 函数对解析树分析并重写并生成查询计划;
- 调用 pg_plan_queries() 对查询树进行优化并选择一条最优路径生成执行计划;
- 创建 Portal 对象并调用 PortalRun() 函数执行查询计划。
- 执行 Portal 的清理工作并转步骤 2;
- 退出。
需要注意的是 DDL 在步骤 3 和步骤 4 时不会被重写或优化,而只是简单的在原始解析树外面包装对应的结构而已,只有到了步骤 5 时才会执行转换并生成查询计划。
sql
CREATE TABLE test (id int, info text);parse tree
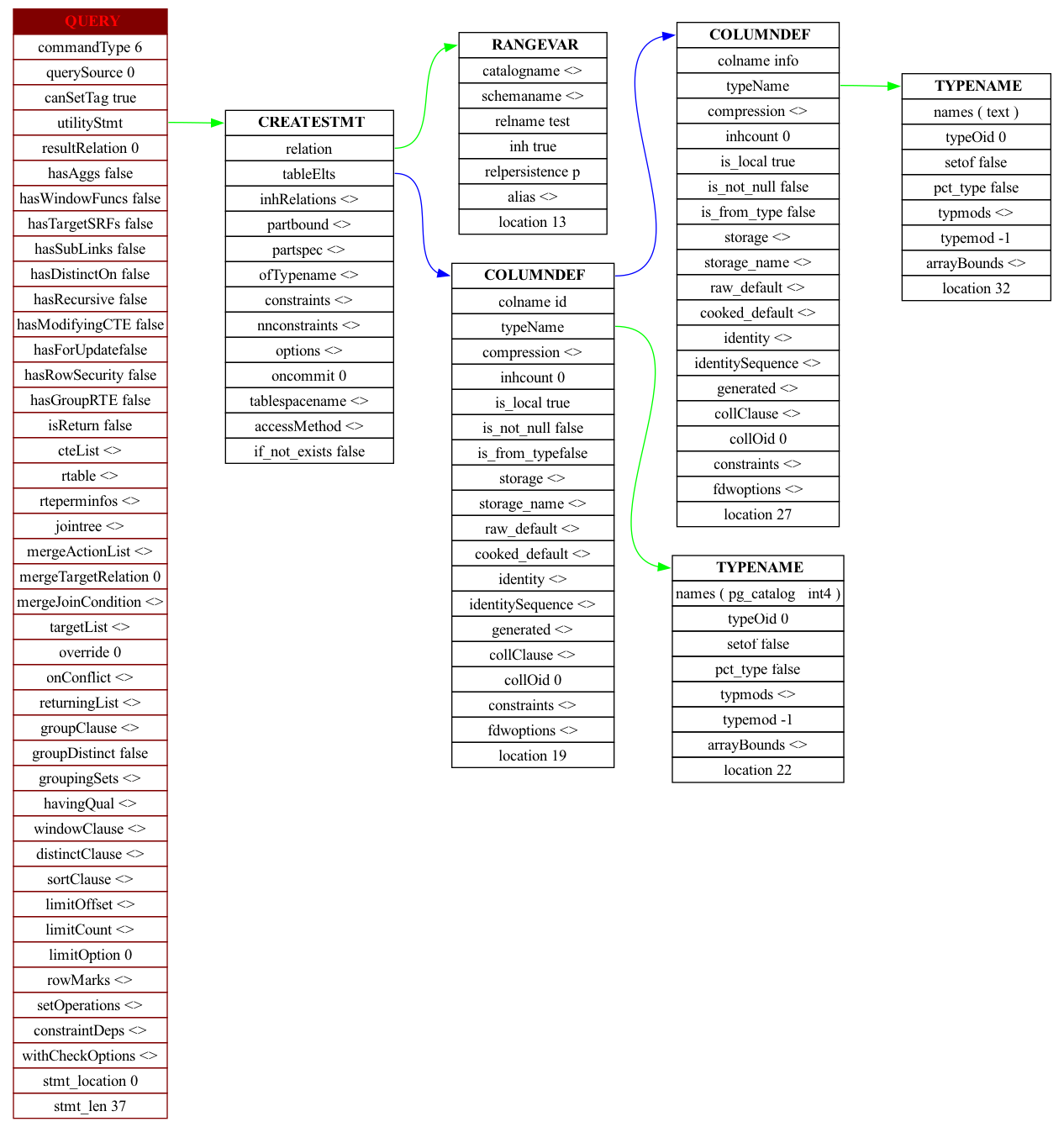
rewritten parse tree
sql
-- 年级信息
drop table if exists tb_grade;
create table tb_grade(
no int,
name varchar(20)
);
-- 班级信息
drop table if exists tb_class;
create table tb_class(
no int,
name varchar(20),
grade_no int
);
-- 学生信息
drop table if exists tb_student;
create table tb_student(
no int,
name varchar(20),
class_no int
);
-- 课程信息
drop table if exists tb_course;
create table tb_course(
no int,
name varchar(20)
);
-- 成绩信息
drop table if exists tb_score;
create table tb_score(
student_no int, -- 学号
course_no int, -- 课程号
score int -- 分数
);
-- 数据
insert into tb_course (no, name) values(1, 'math');
insert into tb_course (no, name) values(2, 'chinese');
insert into tb_course (no, name) values(3, 'english');
-- 查询
select
sub_tb_class.no as class_no,
sub_tb_class.name as class_name,
AVG(score) as avg_score
from
tb_score,
(select * from tb_class where tb_class.grade_no = '2005') as sub_tb_class
where
tb_score.student_no in (
select no from tb_student where tb_student.class_no = sub_tb_class.no
)
AND
tb_score.course_no in (
select no from tb_course where tb_course.name = '高等数学'
)
group by class_no, class_name
having avg(score) > 0
order by avg_score;explain结果
sql
QUERY PLAN
-------------------------------------------------------------------------------------------------------
Sort (cost=104.24..104.24 rows=1 width=94)
Sort Key: (avg(tb_score.score))
-> GroupAggregate (cost=104.20..104.23 rows=1 width=94)
Group Key: tb_class.no, tb_class.name
Filter: (avg(tb_score.score) > '0'::numeric)
-> Sort (cost=104.20..104.20 rows=1 width=66)
Sort Key: tb_class.no, tb_class.name
-> Hash Join (cost=67.82..104.19 rows=1 width=66)
Hash Cond: (tb_score.student_no = tb_student.no)
-> Hash Semi Join (cost=21.30..57.51 rows=41 width=8)
Hash Cond: (tb_score.course_no = tb_course.no)
-> Seq Scan on tb_score (cost=0.00..30.40 rows=2040 width=12)
-> Hash (cost=21.25..21.25 rows=4 width=4)
-> Seq Scan on tb_course (cost=0.00..21.25 rows=4 width=4)
Filter: ((name)::text = '高等数学'::text)
-> Hash (cost=46.49..46.49 rows=2 width=66)
-> Hash Join (cost=43.70..46.49 rows=2 width=66)
Hash Cond: (tb_student.class_no = tb_class.no)
-> HashAggregate (cost=22.90..24.90 rows=200 width=8)
Group Key: tb_student.class_no, tb_student.no
-> Seq Scan on tb_student (cost=0.00..18.60 rows=860 width=8)
-> Hash (cost=20.75..20.75 rows=4 width=62)
-> Seq Scan on tb_class (cost=0.00..20.75 rows=4 width=62)
Filter: (grade_no = 2005)
(24 rows)