拼音分词器
1、安装拼音分词器
下载地址:
https://github.com/medcl/elasticsearch-analysis-pinyin
安装方式与IK分词器一样,分三步:
- 解压
- 上传到虚拟机中,elasticsearch的plugin目录
- 重启elasticsearch
- 测试
详细安装步骤可以参考IK分词器的安装过程。
测试用法如下:
json
POST /_analyze
{
"text": "如家酒店还不错",
"analyzer": "pinyin"
}结果:
json
{
"tokens" : [
{
"token" : "ru",
"start_offset" : 0,
"end_offset" : 0,
"type" : "word",
"position" : 0
},
{
"token" : "rjjdhbc",
"start_offset" : 0,
"end_offset" : 0,
"type" : "word",
"position" : 0
},
{
"token" : "jia",
"start_offset" : 0,
"end_offset" : 0,
"type" : "word",
"position" : 1
},
{
"token" : "jiu",
"start_offset" : 0,
"end_offset" : 0,
"type" : "word",
"position" : 2
},
{
"token" : "dian",
"start_offset" : 0,
"end_offset" : 0,
"type" : "word",
"position" : 3
},
{
"token" : "hai",
"start_offset" : 0,
"end_offset" : 0,
"type" : "word",
"position" : 4
},
{
"token" : "bu",
"start_offset" : 0,
"end_offset" : 0,
"type" : "word",
"position" : 5
},
{
"token" : "cuo",
"start_offset" : 0,
"end_offset" : 0,
"type" : "word",
"position" : 6
}
]
}2、自定义分词器
默认的拼音分词器会将每个汉字单独分为拼音,而我们希望的是每个词条形成一组拼音,需要对拼音分词器做个性化定制,形成自定义分词器。
elasticsearch中分词器(analyzer)的组成包含三部分:
- character filters:在tokenizer之前对文本进行处理。例如删除字符、替换字符
- tokenizer:将文本按照一定的规则切割成词条(term)。例如keyword,就是不分词;还有ik_smart
- tokenizer filter:将tokenizer输出的词条做进一步处理。例如大小写转换、同义词处理、拼音处理等
文档分词时会依次由这三部分来处理文档:
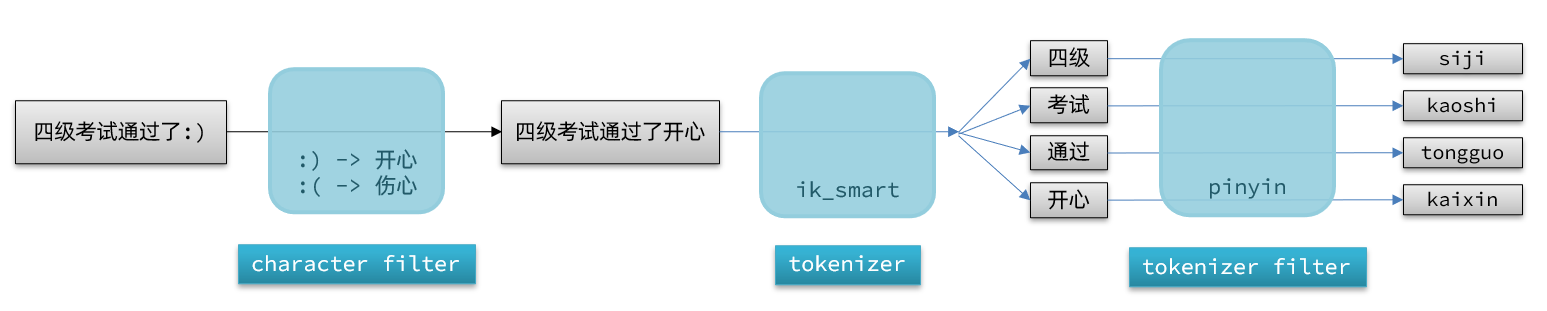
声明自定义分词器的语法如下:
json
PUT /test
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "my_analyzer",
"search_analyzer": "ik_smart"
}
}
}
}参数含义:
- keep_full_pinyin: 刘德华 > [liu,de,hua]
- keep_joined_full_pinyin: 刘德华> [liudehua]
- keep_original: 保留原始输入
- limit_first_letter_length: 设置first_letter结果的最大长度
- remove_duplicated_term: 重复的词项将被删除
- none_chinese_pinyin_tokenize: 如果非汉语字母是拼音,则将其分解为单独的拼音术语
测试:
json
POST /test/_analyze
{
"text": "如家酒店还不错",
"analyzer": "my_analyzer"
}分词结果
json
{
"tokens" : [
{
"token" : "如家",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "rujia",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "rj",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "酒店",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "jiudian",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "jd",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "还不",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "haibu",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "hb",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "不错",
"start_offset" : 5,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "bucuo",
"start_offset" : 5,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "bc",
"start_offset" : 5,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 3
}
]
}示例
json
POST /test/_doc/1
{
"id": 1,
"name": "狮子"
}
POST /test/_doc/2
{
"id": 2,
"name": "虱子"
}
GET /test/_search
{
"query": {
"match": {
"name": "掉入狮子笼咋办"
}
}
}搜索结果
json
{
"took" : 783,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.9530773,
"hits" : [
{
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.9530773,
"_source" : {
"id" : 1,
"name" : "狮子"
}
}
]
}
}3、拼音分词器总结
如何使用拼音分词器?
①下载pinyin分词器
②解压并放到elasticsearch的plugin目录
③重启即可
如何自定义分词器?
①创建索引库时,在settings中配置,可以包含三部分
②character filter
③tokenizer
④filter
拼音分词器注意事项?
- 为了避免搜索到
同音字,搜索时不要使用拼音分词器