并发篇-Hashtable vs ConcurrentHashMap
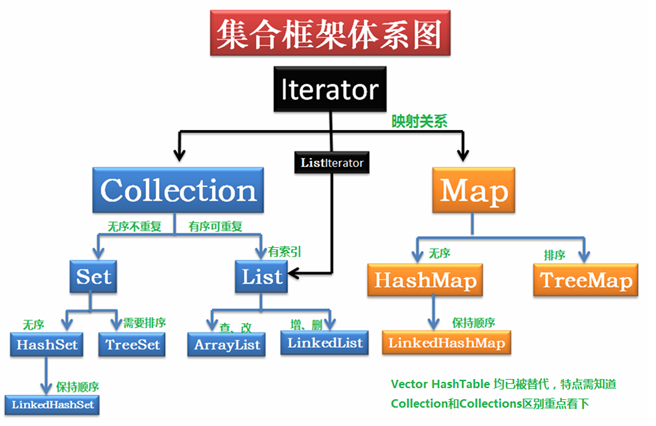
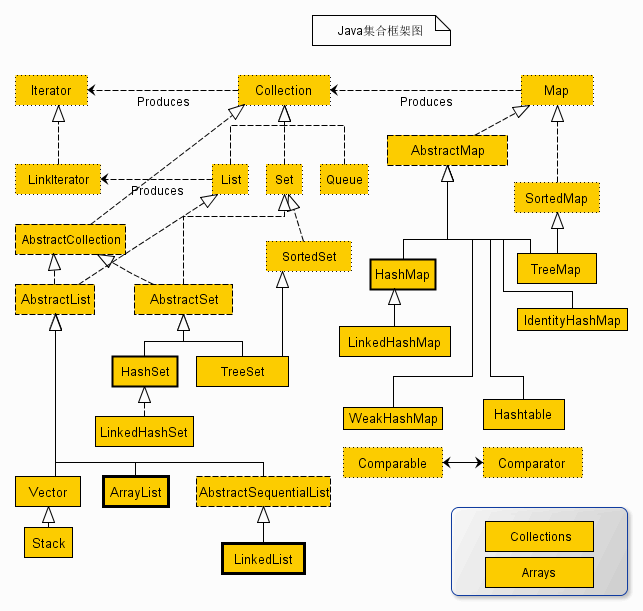 要求
要求
- 掌握 Hashtable 与 ConcurrentHashMap 的区别
- 掌握 ConcurrentHashMap 在不同版本的实现区别
更形象的演示,见资料中的 hash-demo.jar,运行需要 jdk14 以上环境,进入 jar 包目录,执行下面命令
java -jar --add-exports java.base/jdk.internal.misc=ALL-UNNAMED hash-demo.jar
Hashtable 对比 ConcurrentHashMap
- Hashtable 与 ConcurrentHashMap 都是线程安全的 Map 集合
- Hashtable 并发度低,整个 Hashtable 对应一把锁,同一时刻,只能有一个线程操作它
- ConcurrentHashMap 并发度高,整个 ConcurrentHashMap 对应多把锁,只要线程访问的是不同锁,那么不会冲突
ConcurrentHashMap 1.7
- 数据结构:
Segment(大数组) + HashEntry(小数组) + 链表,每个 Segment 对应一把锁,如果多个线程访问不同的 Segment,则不会冲突 - 并发度:Segment 数组大小即并发度,决定了同一时刻最多能有多少个线程并发访问。Segment 数组不能扩容,意味着并发度在 ConcurrentHashMap 创建时就固定了
- 索引计算
- 假设大数组长度是
2^m,key 在大数组内的索引是 key 的二次 hash 值的高 m 位 - 假设小数组长度是
2^n,key 在小数组内的索引是 key 的二次 hash 值的低 n 位
- 假设大数组长度是
- 扩容:每个小数组的扩容相对独立,小数组在超过扩容因子时会触发扩容,每次扩容翻倍
- Segment[0] 原型:首次创建其它小数组时,会以此原型为依据,数组长度,扩容因子都会以原型为准
ConcurrentHashMap 1.8
- 数据结构:
Node 数组 + 链表或红黑树,数组的每个头节点作为锁,如果多个线程访问的头节点不同,则不会冲突。首次生成头节点时如果发生竞争,利用 cas 而非 syncronized,进一步提升性能 - 并发度:Node 数组有多大,并发度就有多大,与 1.7 不同,Node 数组可以扩容
- 扩容条件:Node 数组满 3/4 时就会扩容
- 扩容单位:以链表为单位从后向前迁移链表,迁移完成的将旧数组头节点替换为 ForwardingNode
- 扩容时并发 get
- 根据是否为 ForwardingNode 来决定是在新数组查找还是在旧数组查找,不会阻塞
- 如果链表长度超过 1,则需要对节点进行复制(创建新节点),怕的是节点迁移后 next 指针改变
- 如果链表最后几个元素扩容后索引不变,则节点无需复制
- 扩容时并发 put
- 如果 put 的线程与扩容线程操作的链表是同一个,put 线程会阻塞
- 如果 put 的线程操作的链表还未迁移完成,即头节点不是 ForwardingNode,则可以并发执行
- 如果 put 的线程操作的链表已经迁移完成,即头结点是 ForwardingNode,则可以协助扩容
- 与 1.7 相比是懒惰初始化
- capacity 代表预估的元素个数,capacity / factory 来计算出初始数组大小,需要贴近
2^n - loadFactor 只在计算初始数组大小时被使用,之后扩容固定为 3/4
- 超过树化阈值时的扩容问题,如果容量已经是 64,直接树化,否则在原来容量基础上做 3 轮扩容
Hashtable
- 初始容量:
11 - 扩容规律:
(上一次容量 * 2)+ 1
部分源码
java
public class Hashtable<K,V>{
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
private int threshold;
public Hashtable(int initialCapacity, float loadFactor) {
// 11 * 0.75 = 8.25 取 8
threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
}
public Hashtable() {
// 3/4 = 0.75
this(11, 0.75f);
}
protected void rehash() {
// 扩容规律 (oldCapacity * 2)+ 1
int newCapacity = (oldCapacity << 1) + 1;
// 扩容临界值
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
}
private void addEntry(int hash, K key, V value, int index) {
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
rehash();
}
count++;
}
public synchronized V put(K key, V value) {}
}第一次扩容(添加第9个值的时候)
临界值:
11 * 3/4 = 8.25 取 8
第一次扩容后的结果:
11 * 2 + 1 = 23java
public class ConcurrentHashMap<K,V>{
private static final int DEFAULT_CAPACITY = 16;
}测试代码
java
package com.demo;
import org.springframework.util.StopWatch;
import java.util.HashMap;
import java.util.Hashtable;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.CountDownLatch;
public class HashTableDemo {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
//Map<String, String> map = new Hashtable<>();
//Map<String, String> map = new ConcurrentHashMap<>();
int count = 100 * 10000;
CountDownLatch countDownLatch = new CountDownLatch(count);
StopWatch stopWatch = new StopWatch();
stopWatch.start();
for (int i = 0; i < count; i++) {
new Thread(() -> {
map.put(Thread.currentThread().getName(), "value");
countDownLatch.countDown();
}, "t"+i).start();
}
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
stopWatch.stop();
System.out.println(stopWatch.getTotalTimeMillis());
// 72957
System.out.println(map.size());
// 1000000
}
}| 实现类 | 耗时(单位:毫秒) |
|---|---|
| ConcurrentHashMap | 72957 |
| Hashtable | 78241 |
| HashMap | 68306 |